
【前半】では、Transformerがざっくりとどんなものなのかを説明させていただきました。Transformerは現在の自然言語処理の分野で標準となっているモデルであり、しっかりと理解したいところです。
さて今回はTransformerの詳細と、その驚くべき結果について説明していきたいと思います。モデルの詳細はかなり難解です。医療者でも理解できることを目指して記載してますが、一度で理解するのは難しいので、必要でなければ読み飛ばしても良いと思います。また、他の記事も併せて読んでいただきながら、少しづつ理解していただければと思います。
モデルの詳細
まず論文に掲載されているモデルは以下の通りです。
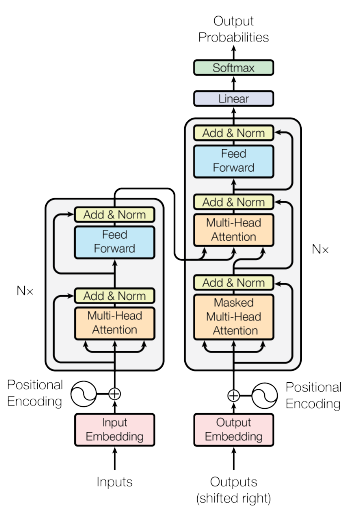
はっきり言って何のことかさっぱりわかりませんね。
まず、図の、左半分がエンコーダ、右半分がデコーダです。
エンコーダ-デコーダ構造
英語から日本語への翻訳を例にとると、エンコーダは英語の文章を一度別のデータに変換するもの、デコーダはそのデータから日本語の文章を取り出すものです。
その場合、エンコーダの入力は「I love Japan」、デコーダの入力は「私は 日本が 〇〇」になります。〇〇を部分を予測するのがこのモデルの目的になります。
デコーダには〇〇の部分が隠されて入力されるので、Masked Multi-Head Attentionという言葉が用いられます。
一つ一つの項目を、順番に見ていきたいと思います。
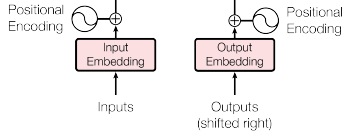
Input Embedding と OutputEmbedding
入力される単語は、他データで訓練済みのEmbedding(埋め込み)層によって、ベクトルに変換されます。
Positional Encoding
次に位置エンコードが足しあわされます。これによって、単語が文の中で出現する順番が考慮されるようになります。位置エンコードの計算には、サインとコサインが使われているため、図の中ではサインカーブが描かれています。
Multi-Head Attention(複数ヘッドAttention)
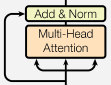
これがこのモデルの最も難解なところである一方、キモとなる部分です。まずAttentionとは何でしょうか?
Attention(注目)は、ある単語の意味を理解するときに、文中の他の単語に注目することです。例えば、「The beer is cold」という文があるとき、coldが「冷たい」「寒い」「風邪」のどれを意味しているかは、coldだけ眺めていてもわかりませんよね。「このビールは冷たい」と正しく訳すためには、beerという単語も注目(Attention)しないといけないのです。
まず各単語にそれぞれ、クエリ(Q)、キー(K)、バリュー(V)の3つのベクトルを与えます。次に、QとKの掛け算でAttentionスコアを計算します。これを用いてVを加重和すると、その単語に対するAttentionが得られます。
さらに、これを応用したのがMulti-Head Attentionです。各単語に対して1組の(Q, K, V)を与えるのではなく、8組の(Q, K, V)を与えます。これによって、色んな種類のAttentionが抽出されるので、性能が向上します。
Add and Normalization
Addは残差結合のことです。残差結合とは、画像認識における革新的なモデルとなったResNetで使われた方法です。ある層のインプットと、アウトプットを足し合わせたものを、最終的なアウトプットとして用いることで、性能が向上します。
Normalizationは正規化を意味します。バッチ正規化は広く使われている手法ですが、ここではレイヤー正規化という、改良版が用いられています。
Feed Forward Network
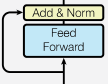
Multi-Head Attentionの後に入っているこれは、各単語ごとに独立した、2層のニューラルネットワークです。
最終出力
エンコーダの最終出力からQとK、デコーダのMasked Multi-Head Attentionの出力からVが集められ、Multi-Head Attentionに入力されます。その後デコーダ内でFeed Forward Network、Linear(線形変換)、Softmax関数が施され、翻訳結果が出力されます。
学習
データとしてWMT2014英語→ドイツ語(450万ペア)と、WMT2014英語→フランス語(3600万ペア)が用いられました。
GPU(ディープラーニングに必要な、並列計算をさせる部品)には、NVIDIA P100を8個用いた。それぞれのデータの学習にかかった時間は12時間、および3.5日でした。
モデルの最適化には「Adam」を用い、学習が進むにつれて学習率を変化させました。
過学習を防ぐために、ドロップアウトとラベルスムージングという手法を使用しました。
結果
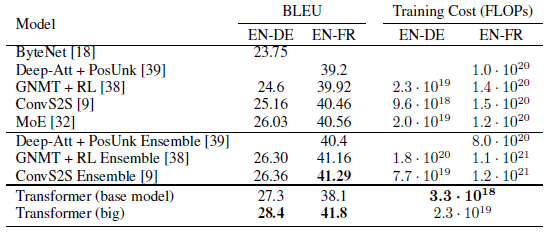
BLEU(Bilingual Evaluation Understudy Score)は、現在最も広く使用されている機械翻訳の評価方法です。スコアが100に近ければ近いほど評価が高くなります。目安としては、スコアが40以上であれば高品質といえます。
Transformerは過去のモデルと比較して、最高のパフォーマンスを叩き出しました。一方で、計算量を大きく減らすことができました。
まとめ
かなり難しい論文でしたが、あの自然言語処理の最強モデルGPT-2の基礎となっているモデルであり、またCTやMRIなどの配列をなしていることが多い医療画像の認識において今後必須のモデルになると思います。
この記事を読んで、もし少しでも何かを学べたらうれしいです。今後もホットなモデルを、医療者でも理解しやすいように解説していきたいと思います。


コメント