
はじめに
EfficientNetは2019年5月に発表されましたが、少ないパラメータで非常に高い精度を有し、NFNetなどの最新のモデルと比較されることが多いモデルです。今回はこのモデルを、非専門家の方でも概要がつかめるよう、わかりやすく解説していきたいと思います。
引用論文:EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks, https://arxiv.org/abs/1905.11946
背景
Deep learningの精度を高めるために、モデルを大きくすることは有効です。例えばGPipeというモデルは、ResNet(レズネット、有名なモデルの一つ)を4倍大きくする(スケールアップする)ことで、SOTA(State-of-the-art、歴代最高水準のこと)を達成しました。しかし近年モデルはどんどん大きくなり、コンピュータのメモリに納まらなくなります。効率的なスケールアップの方法は明らかになっていません。
スケールアップで一般的なのは、層の数(depth)と、チャンネル数(width)を増やすことです。また最近では、画像の解像度(resolution)を増やす手法も人気です。これらは手作業で行われますが、骨が折れる割に精度が上がりません。
小さなモデルの効率化に、Neural architecture search (NAS)という手法が有効であることがわかりました。しかし、これが大きなモデルでも機能するかは不明でした。
本研究では、モデルのスケールアップにおける原理原則を見つけます。
Compound Model Scaling(複合モデルスケーリング)
従来はd (depth)、w (width)、r (resolution) の1つだけをスケールアップしていました。しかし例えば、wを大きくしてもdが小さければ、画像の複雑な特徴をつかむことはできません。そこで、d, w, r を同時に大きくするようにします。d, w, r を以下の式で決めます。
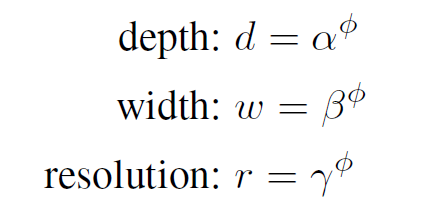
まずφが1の時の、最適なα、β、γを求めます。そしてφを徐々に大きくすることでd, w, r をスケールアップしていきます。
計算量をコントロールするために以下の条件をつけます。※dを2倍にすると計算量は2倍に、w, rを2倍にすると計算量はそれぞれ4倍になることが知られていますので、αだけ2乗がついてません。
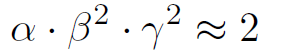
EfficientNet
NASを用いることで、α=1.2, β=1.1, γ=1.15が最適であることがわかりました。この基礎モデルをEfficientNet-B0とします。そしてφを徐々に大きくすることでEfficientNet-B1~B7を作成していきます。
訓練
ImageNetデータ(最も有名なデータの一つ)を学習させました。
※ 詳細:RMSprop(decay 0.9、momentum 0.9)、batch norm momentum 0.99、weight decay 0.00001、learning rate 0.256から開始⇒2.4 epochごとに0.97倍、SiLU、AutoAugment、Stochastic depth、Dropout使用
結果
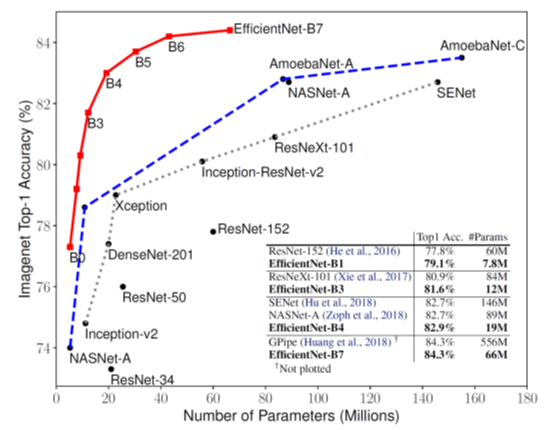
EfficientNet(上図、赤線)は、少ないパラメータで、高い正答率を達成しています。EfficientNet-B7(上図、右下の表)は、現存するモデルより8.4倍小さく、6.4倍速かったにもかかわらず、正答率84.3%を叩き出し、SOTAを更新しました。
Transfer learning(転移学習、あらかじめ訓練済みのモデルを使い精度を高める手法)でもEfficientNetを試してみたところ、CIFAR-100(有名なデータセットの一つ)を含む5つのデータセットでSOTAを更新しました。
まとめ
層の数、チャンネル数、画像の解像度を同時に増やすことで、精度を維持してパラメータを大幅に削減することができました。引き続き、存在感のあるモデルになっていくと思います。
今回は非専門家の方でも概要がつかめるように、なるべくわかりやすく解説することを心がけました。この記事が、少しでも読んでいただいた方の参考になれば嬉しいです。

コメント